

Blog Post
SEO

Nadine
Wolff
published on:
15.03.2019

robots.txt – A Stop Sign for Search Engine Bots?
Table of Contents

Search engine bots (also known as robots, spiders, or user agents) crawl the web daily in search of new content. Their mission is to analyze and index web pages. However, before these crawlers start their work, they must first pass by the robots.txt file. The so-called "Robots Exclusion Standard Protocol" was first published in 1994 and regulates the behavior of search engine bots on websites.
Unless otherwise specified, bots can crawl your website unrestrictedly. Creating a robots.txt file can also help protect certain pages or individual elements from the view of web spiders. This article explains in which cases creating a robots.txt is sensible and what you should pay attention to when generating and testing the file.
When a search engine bot lands on your website, it aims to crawl as many pages and content as possible. With the proper instructions in the robots.txt file, you can directly inform the search bots which content is relevant. In other cases, sensitive data can be protected, non-public directories excluded, or test environments temporarily hidden.
Right upfront: There's no guarantee that crawlers will adhere to the prohibitions set in the robots.txt file! The specified instructions are merely guidelines and cannot enforce specific behavior from the crawlers. Hackers and scrapers cannot be stopped by the robots.txt file. However, experience shows that at least the most well-known search engines like Google or Bing comply with the rules. You can read a detailed article on how crawling works in our blog post “Crawling – the spider on your website“.
Moreover, prohibitions in the robots.txt file are not necessarily the method of choice if you want to prevent indexing by search engines. Especially websites with strong interlinking may still appear in the search results. In such cases, affected pages or files should instead be protected with the Meta Robots Tag "noindex".
The robots.txt file is always located in the root directory of your website. The robots.txt file can be accessed as follows: Enter the URL of the website in the browser's address bar and append /robots.txt to the domain. If no file is present yet, there are various ways to properly create and test the robots.txt file.
Creating a robots.txt – it's all about the right syntax
There are now numerous free tools and generators available online with which the robots.txt file can be automatically created. If you prefer not to use a generator and wish to create your file manually, you can use a plain text editor or the Google Search Console. The Google Search Console can also be used to test the correct creation of the robots.txt file afterwards.
Every robots.txt contains datasets, also known as "records". Each record consists of two parts. To ensure the rules set can be effective, the correct syntax must be used.
To set instructions and prohibitions, the respective crawler must first be addressed with the "User Agent" command. In the second part, further rules for the bots are introduced with the "Disallow" command. If a page or element is not blocked by Disallow, the user agent will crawl all content by default.
The basic scheme for structuring a dataset is as follows:
User-Agent: *
Disallow:
Another option would be the use of the "Allow" command, which explicitly permits crawling in contrast to Disallow:
User Agent: *
Allow: /
With these instructions, all crawlers are allowed to access all resources. The wildcard asterisk is considered as a variable for all crawlers. All instructions are processed from top to bottom. When creating the rules, the correct use of uppercase and lowercase letters must also be ensured. In the following example, only the Googlebot is prohibited from accessing a subpage of the website:
User-Agent: Googlebot
Disallow: /subpage.html
With the "User Agent" directive, only one search engine bot can be addressed at a time. If different bots are to be addressed, an additional block is required in the robots.txt file. This is also constructed according to the basic scheme. A blank line is inserted between the lines:
User-Agent: Bingbot
Disallow: /directory1/
User-Agent: Googlebot
Disallow: /shop/
In this example, the Bingbot is not allowed to access directory 1, while the Googlebot is prohibited from crawling the site's shop. Alternatively, the same instructions for different bots can also be noted directly under each other:
User-Agent: Bingbot
User-Agent: Googlebot
Disallow: /shop/
Overview of the most well-known search engine crawlers:
Correctly excluding website content
As the last examples show, indications for files and directories typically begin behind the domain with a slash "/". Following that is the path. Always remember to include the slash at the end of the directory name. It should be noted that with the slash at the end, further subdirectories can still be crawled by the bots. To avoid this, simply omit the slash at the end.
In the original protocol, it was not intended to explicitly allow individual pages or elements for indexing. However, Allow can also be used during creation to release subdirectories or files in otherwise restricted directories for bots:
User-Agent: *
Disallow: /Images/
Allow: /Images/public/
To block specific files (e.g., PDFs or images), it is recommended to add a "$" at the end of the file name. This indicates that no further characters may follow:
User-Agent: *
Disallow: /*.gif$
Additionally, it is recommended to include a reference to the sitemap within the robots.txt file. Why it makes sense to use a sitemap for your website and how to create it properly can be read in our blog post “The perfect sitemap“: To add the sitemap, a simple additional line is sufficient:
User-Agent: *
Disallow:
Sitemap: https://YourWebsiteName.com/sitemap.xml
Properly testing the robots.txt file
After creation, the robots.txt should be tested because even minor errors can lead to the file being ignored by crawlers. With the Google Search Console, you can check if the syntax of the file has been correctly established. The robots.txt tester checks your file just as the Googlebot would, to ensure the corresponding files are effectively blocked. Simply enter the URL of your site into the text field at the bottom of the page. The robots.txt tester can even be used before you upload the file to the root directory. Just enter the syntax into the input field:
[caption id="attachment_23758" align="aligncenter" width="758"]
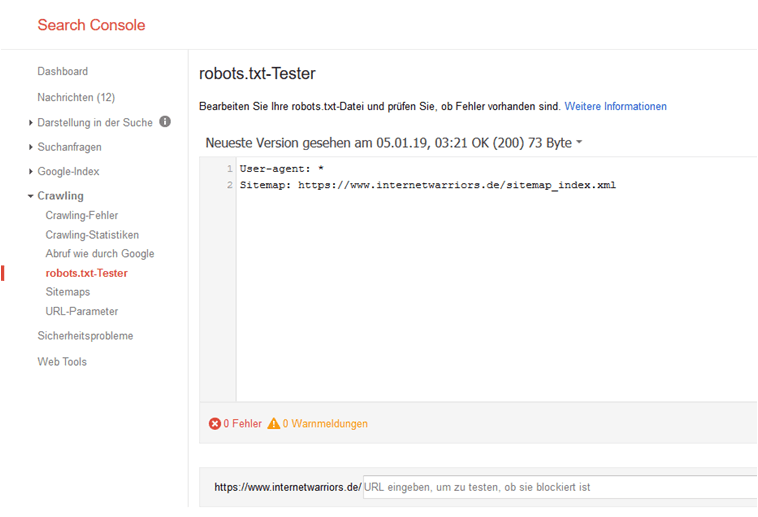
Figure 1: Screenshot of the robots.txt tester from the Search Console[/caption]
Once no error messages are displayed, you can upload the robots.txt file to the root directory of the website. At the time of writing this article, the robots.txt tester from the old version of the Google Search Console was used as an example. In the new GSC version, the robots.txt tester is currently not available.
Conclusion:
The robots.txt file sets the overall framework for search engine bots and can help hide pages or individual files from crawlers. However, there is no guarantee that the rules will be strictly followed. To be absolutely sure and prevent indexing of the site, the "noindex" Meta tag should also be used. When creating the robots.txt, it is essential to use the correct syntax. Tools like the Google Search Console can be used to verify the file.
What can we do for you?
Do you want to implement a robots.txt file on your website? Do you have questions about creating, testing, or embedding your robots.txt file? We are more than happy to assist you in answering and implementing your requests. We look forward to your contact!
Nadine
Wolff
As a long-time expert in SEO (and web analytics), Nadine Wolff has been working with internetwarriors since 2015. She leads the SEO & Web Analytics team and is passionate about all the (sometimes quirky) innovations from Google and the other major search engines. In the SEO field, Nadine has published articles in Website Boosting and looks forward to professional workshops and sustainable organic exchanges.
